


Deep Stationコラム第一回「Deep Stationで始めるディープラーニング」
ディープラーニングで何が出来るか?精度は?また、どのような注意点や難点があるのか?不定期連載第一回!
GPUワークステーションにOS、各種ライブラリとソフトウェアをインストールしたディープラーニングのためのオールインワンシステム、Deep Stationの異常検知アルゴリズムについてご紹介いたします。
- 導入いただいた製品
- Deep Stationコラム第一回「Deep Stationで始めるディープラーニング」
- ご導入前の課題
- Deep Stationコラム第一回「Deep Stationで始めるディープラーニング」
- ニューテックを選んだ理由
- Deep Stationコラム第一回「Deep Stationで始めるディープラーニング」
|
本ページに記載された技術情報は記事が出稿された時期に応じて推奨システムに対する考え方や実現方法が書かれています。 |
本コラムを読んでDeep Stationにご興味をお持ち頂けましたら、以下の特設ページをご参照ください。
Deep Station特設ページ
ディープラーニングで何が出来るか、どの程度の精度が出るのか、また、どのような注意点や難点があるかについて知るには、実際にディープラーニングのアルゴリズムを用いたAIモデルを作成してみると理解が早いです。
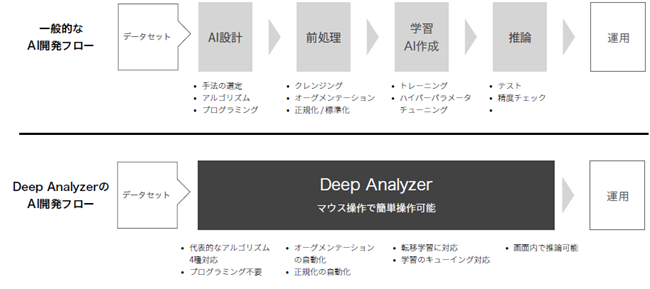
開発環境の構築が年々容易になっているとはいえ、開発には以下の図の上段の機能が必要であり、自分で全ての環境を構築するには多くの時間がかかります。
また、ハードウェア構成によっては、開発環境の基本となるNVIDIAのドライバやCudaのインストールがすんなりと出来ないこともいまだにあります。
Deep Stationであれば、上図の下段のように、専用開発環境であるDeep Analyzerがこれらの機能を備えているため、開発に適したデータさえあれば製品到着後、すぐに開発を始めることが出来ます。
AI開発用途の場合、AI開発の学習用途の場合、いずれにしましても、開発環境の構築や予備知識無しですぐに始められることは大きなメリットと言えます。
ディープラーニングの代表的なアルゴリズムは画像分類になりますが、画像分類の場合は分類させたい内容によって複数の種類の画像が必要になります。
サンプル用のフリーのデータセット(画像)はインターネットに数多くありますので、まず試してみたい場合は「Image Classification dataset」等のキーワードでWeb検索をしてみて下さい。
画像分類に関しては、既に十分な検討がなされており既存のアルゴリズムで高い精度が出せるため、本コラムでは、昨年12月にDeep Analyzerに追加された異常検知アルゴリズムをご紹介致します。
工業製品等の異常検知分野においても画像分類アルゴリズムは活用されていますが、異常な状態の画像を集めることが難しい対象(加工精度が高い工業部品等)に対しては適用しづらいという難点がありました。
そこで、正常な状態の画像のみを用いて学習を行ない、正常な画像と対象画像を比較することで異常であるかどうかを判定するという異常検知の手法が考えられました。
学習用の画像枚数は最低でも2000枚程度必要(同一画像のコピーは不可)になりますが、正常な画像のみあれば学習可能という点が、判定対象によっては大きな強みとなります。
まずは画像を見て頂くとわかりやすいと思いますので、以下に画像を交えて説明を致します。
(操作方法については、前述のURLに記載及び操作動画へのリンクがありますので、そちらをご参照下さい)
学習用画像
これはトランジスタの例になります。
Data Augmentation(データオーグメンテーション)という手法にて、微細なノイズを加えたり位置を少しだけずらしたりすることで、オリジナル画像の水増しをしています。
この例では、10枚の画像をそれぞれ500枚に水増しし、合計5000枚の学習用画像を用意しています。

学習結果
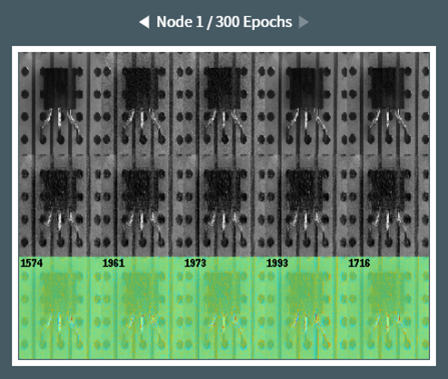
学習が終わると、ネットワーク(AI)の確認メニューにて、以下のように学習結果が表示されます。
これは学習状況を示す画像ですが、上段が判定元の画像、中段がこのAIが正常の基準とする、比較用の画像、下段が比較(推論)結果の画像です。
推論結果は、正常画像との差分をスコアとして表示し、画像の中でどこを異常と判断したかを色分けしています。
判定結果が期待通りではない場合、判定結果からデータセットの見直しをしたり、学習用パラメータの変更をして追試をしたりすることで精度の向上を図ります。
こういったディープラーニングでのAI開発における試行錯誤においても、開発環境の整備で手間が掛からないDeep Station(Deep Analyzer)は向いていると言えます。
ここからは実際の推論結果を見ていきましょう。
推論結果の見方について
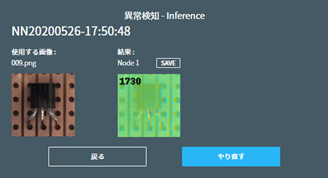
推論画像の数値及び、各色の箇所が表す内容は以下になります。
- 数値
- 正常な画像との差分をスコア化したものです。 最大値は概ね画像のピクセル数になります。
(縦128ピクセル x 横128ピクセルの場合、16384)
- 赤
正しい特徴と入力画像との差分 = 異常部分
- 青
- 正しい特徴の範囲かつ入力画像と一致していない部分(水色も含む)
- 緑
- 正しい特徴と入力画像の一致している部分
平たく言うと赤と青の部分が正常な画像と合っていないピクセルになります。
- あるべきものが無い:青系
- 無かったものがある:赤系
推論結果
(1) 正常な画像の推論
以下のようになりました。
今回使用のテスト画像では、2200~2400程度のスコアが正常の目安となります。
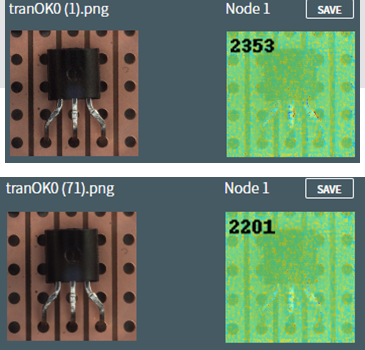
以下は正常な画像なのですが、右側の推論画像を見ると、基板の穴位置がずれている箇所が赤くなっています。
また、足の部分の陰影の差によっても赤くなっている箇所があります。

アルゴリズムによりますが、このように、写真の構図や光の当たり方が均一でないと、本来の意図とは違った形でスコアに差分が出てしまい、判定精度に影響をする場合があります。
既存のビッグデータの活用と謳われているディープラーニングですが、精度の高いAIを作成したい場合には、学習用の画像を準備する段階から注意をする必要があります。
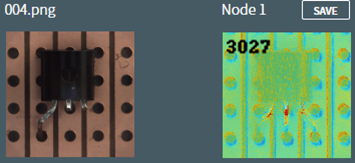
撮影条件が悪いと、以下のように正常な画像であるにも関わらず、高い異常スコアになる場合があります。
(写真が全体的に少しずれているため、特に穴位置のずれによって赤や水色で異常判定されている部分が多くなっています)

(2) 異常画像
異常のパターンとしては、「足が穴から外れている」、「足が切断されている」、「本体部分の損傷」「位置ずれ」となります。
- 以下は足が外れているパターンです。 外れている足の辺りが水色になっています。
但し、足の付け根の辺りの陰影の差の部分も赤くなっています。

- 以下は足の切断です。
こちらも、足の切断部が水色になっていますが、足の付け根も赤くなっています。

2本切断の場合も同様です。 穴の位置ずれによる異常判定が多く見られます。
- 本体の損傷
上部の欠けている箇所が青くなっており、あるべきものが無いと判定されていることがわかります。

- こちらは損傷範囲が小さいですが、水色となっており、損傷が認識されています。

- 位置ずれ
斜めにずれていますが、本体部の正常な位置からはみ出した部分が赤く、ずれて本体が無くなっている部分が青くなっています。

- 実装無し
本来実装されているべき位置が青くなっています。

今回は以上になります。
次回は背景に影響されにくい、別の素材を用いた実例を掲載予定です。
(2020年7月掲載)



